
Intelligent Unsupervised Network Traffic Classification Method Using Adversarial Training and Deep Clustering for Secure Internet of Things †

Abstract
:1. Introduction
- We propose a new unsupervised NTC method based on adversarial training and deep clustering, where deep clustering can learn more features on the basis of pretraining, and maintain the stability of the detector.
- To avoid a cluster collapse due to deep clustering, we apply a combination of cluster loss and adversarial training loss instead of a single cross-entropy loss. At the same time, CAAE is introduced to reduce the dimension of the feature, which avoids the high complexity of the deep learning model caused by the high-dimensional original network traffic features.
- We evaluate the proposed method on network traffic datasets collected in the real environment. The experimental results show that this method has a good clustering effect, and the multiclassification accuracy reaches 92.2%, which is suitable for industrial scenes with a large number of unlabeled data samples.
2. Related Work
2.1. Traditional NTC Methods
2.2. DL-Based NTC Methods
- Robust classification performance: In a real network scenario, any undetected attack may cause the network to crash, resulting in huge losses. Hence, the main goal of NTC method is to continue to accurately classify ordinary traffic and malicious attacks in normal network scenarios.
- Strong model generalization ability: IoT devices are subject to fast-changing attacks, a large number of attacks, and attacks that are good at disguising. Hence, it is necessary to detect with a model that is well adapted to attacks of unknown categories.
- Low model complexity: Network traffic has a large quantity of sample data; hence, it is necessary to use a simple classification model to reduce the detection cost.
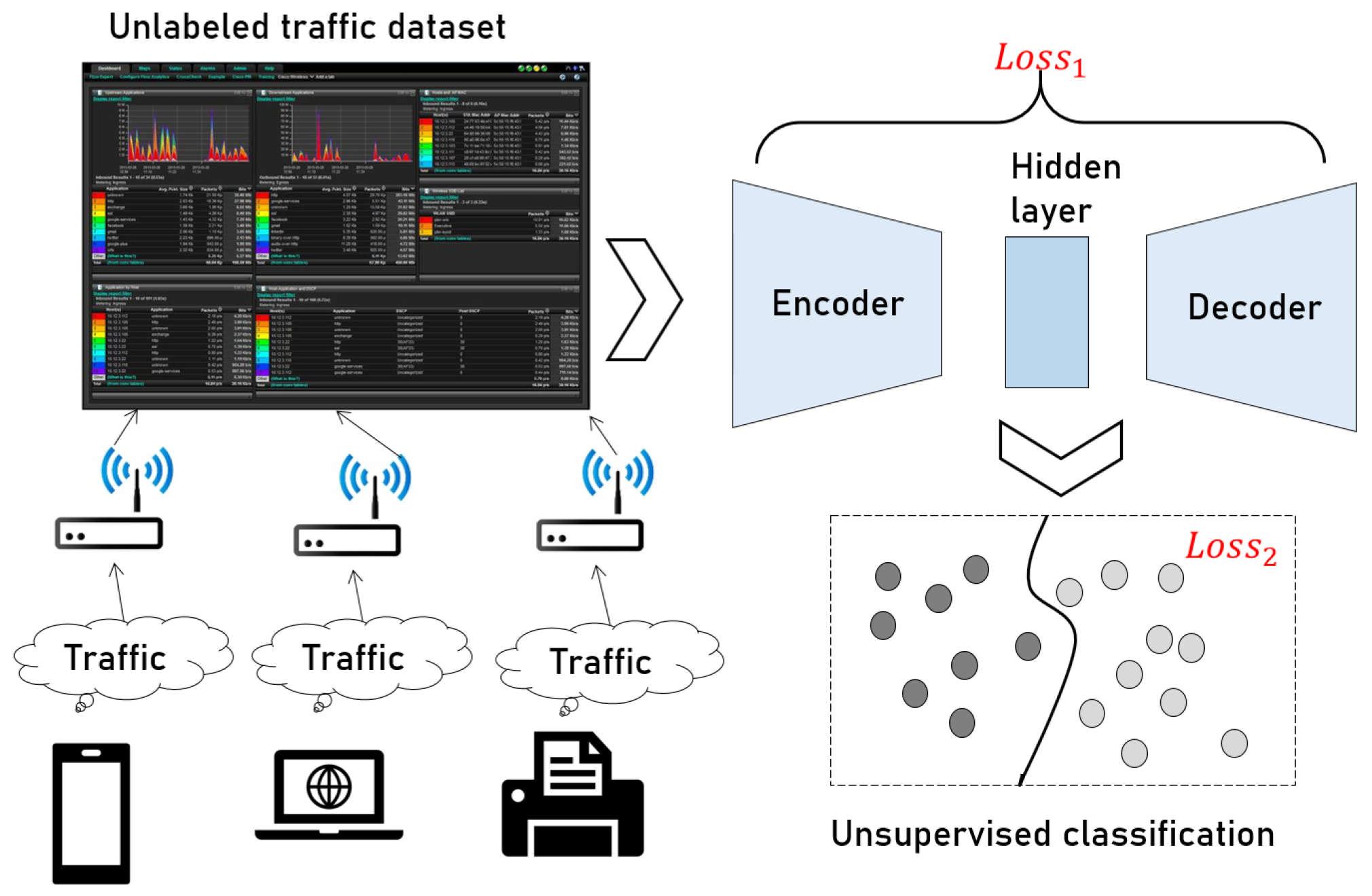
3. Problem Formulation and Dataset Generation
3.1. Problem Description
- Randomly set initial cluster centers, and k represents the number of clusters.
- For each sample data point , where n is greater than k, each object has attributes of m dimensions. Calculate its distance from the center of each cluster and divide each sample into the nearest cluster.
- Recalculate the average value of each cluster as the new cluster center, and update the original cluster center.
- Repeat the above two or three steps to iterate continuously until the center of each cluster does not change.
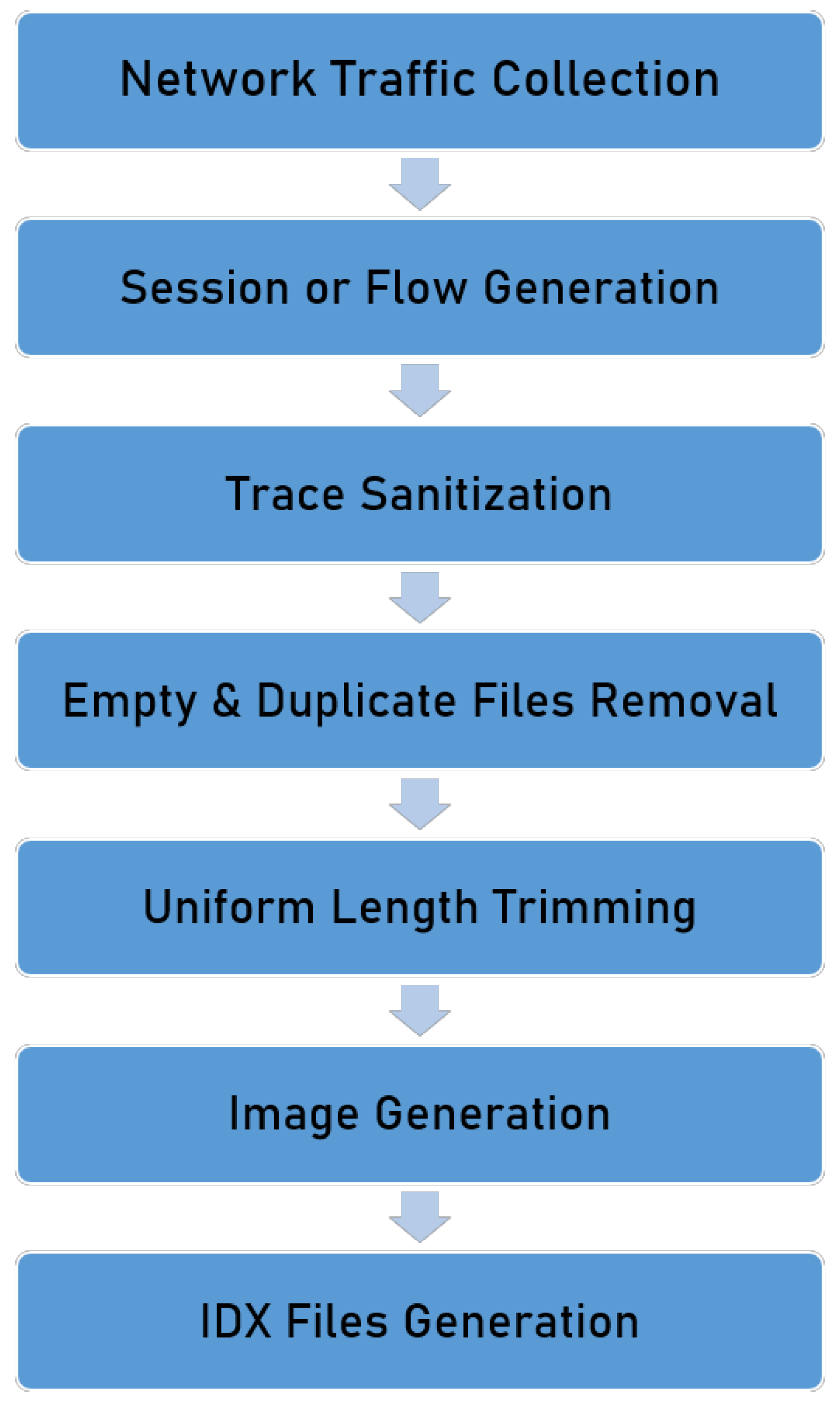
3.2. Dataset Introduction
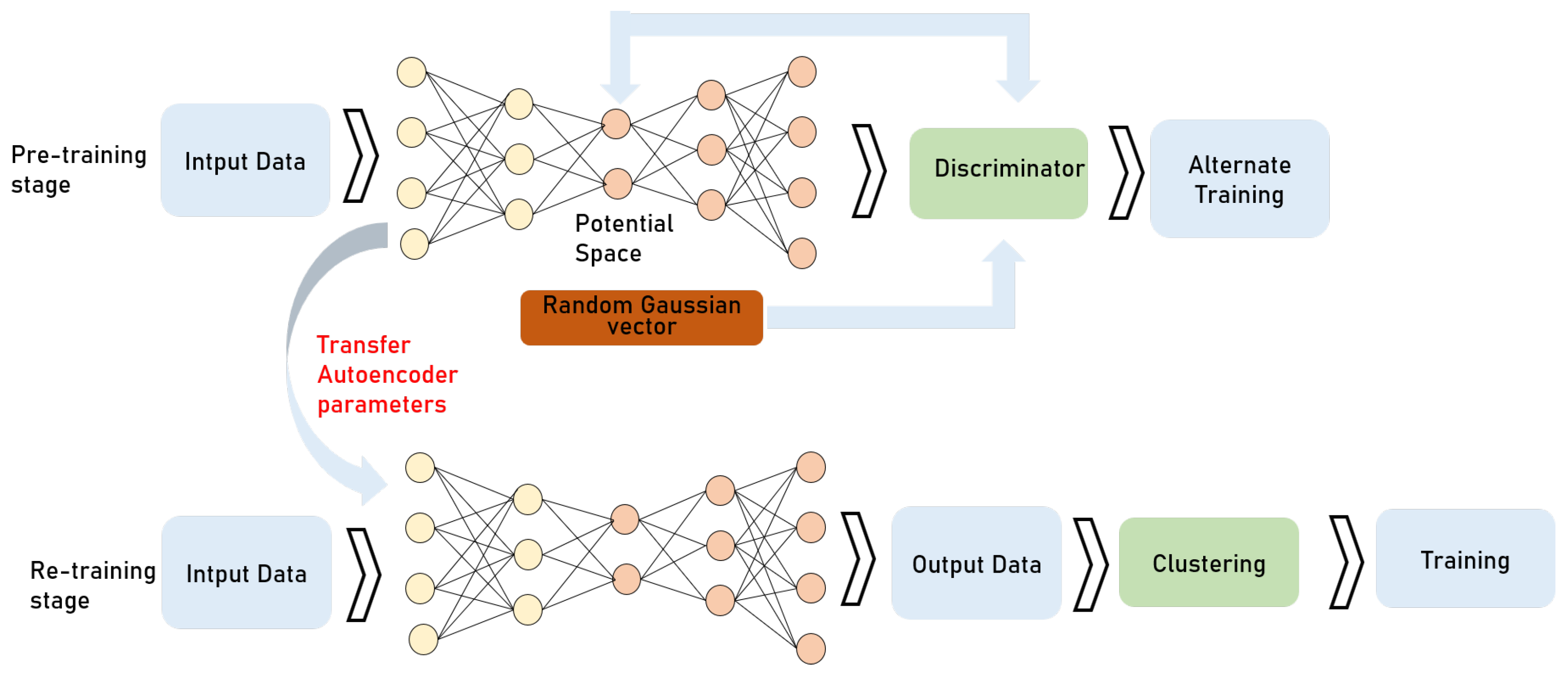
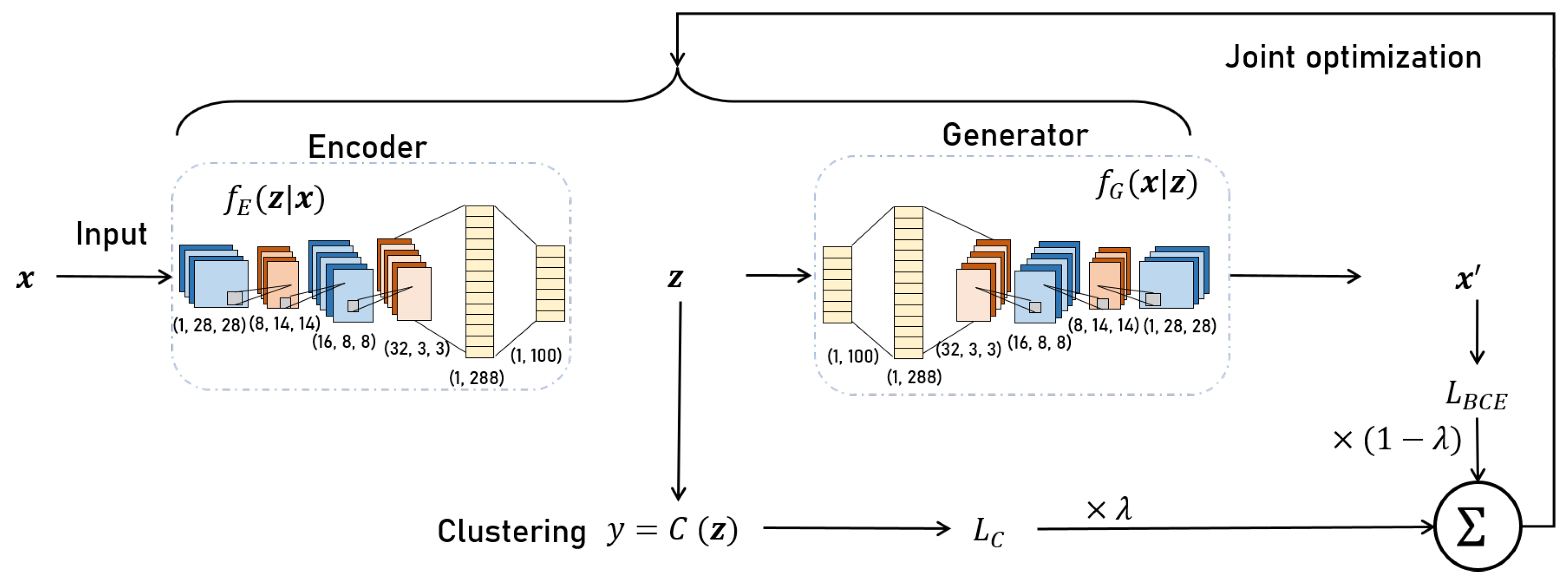
4. The Proposed DC-CAAE Method
| Algorithm 1 Pseudocode of the proposed adversarial-training-based DC-CAAE method for NTC. |
|
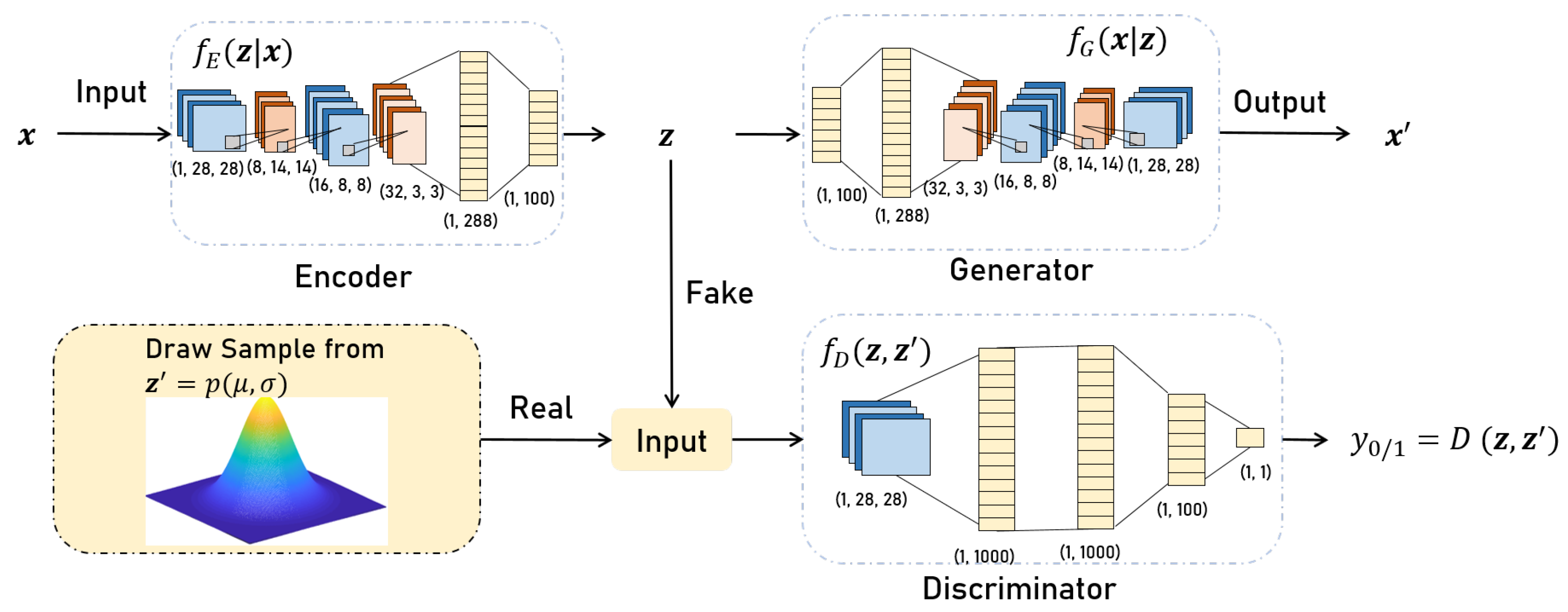
4.1. CAAE Structure
4.2. The Basic Principles of the CAAE
4.3. CAAE Training Process
4.4. Deep Clustering Structure
4.5. The Basic Principles of Deep Clustering
4.6. Deep Clustering Training Process
4.7. The Benchmark Methods
4.7.1. PCA-Based Methods
4.7.2. CAE/CVAE-Based Methods
4.7.3. DC-Based Methods
5. Simulation Results and Discussions
5.1. Simulation Setup and Evaluation Metrics
5.1.1. Simulation Setup
5.1.2. Evaluation Metrics
5.2. Simulation Results and Analysis
5.2.1. Performance Comparison of Unsupervised NTC Methods
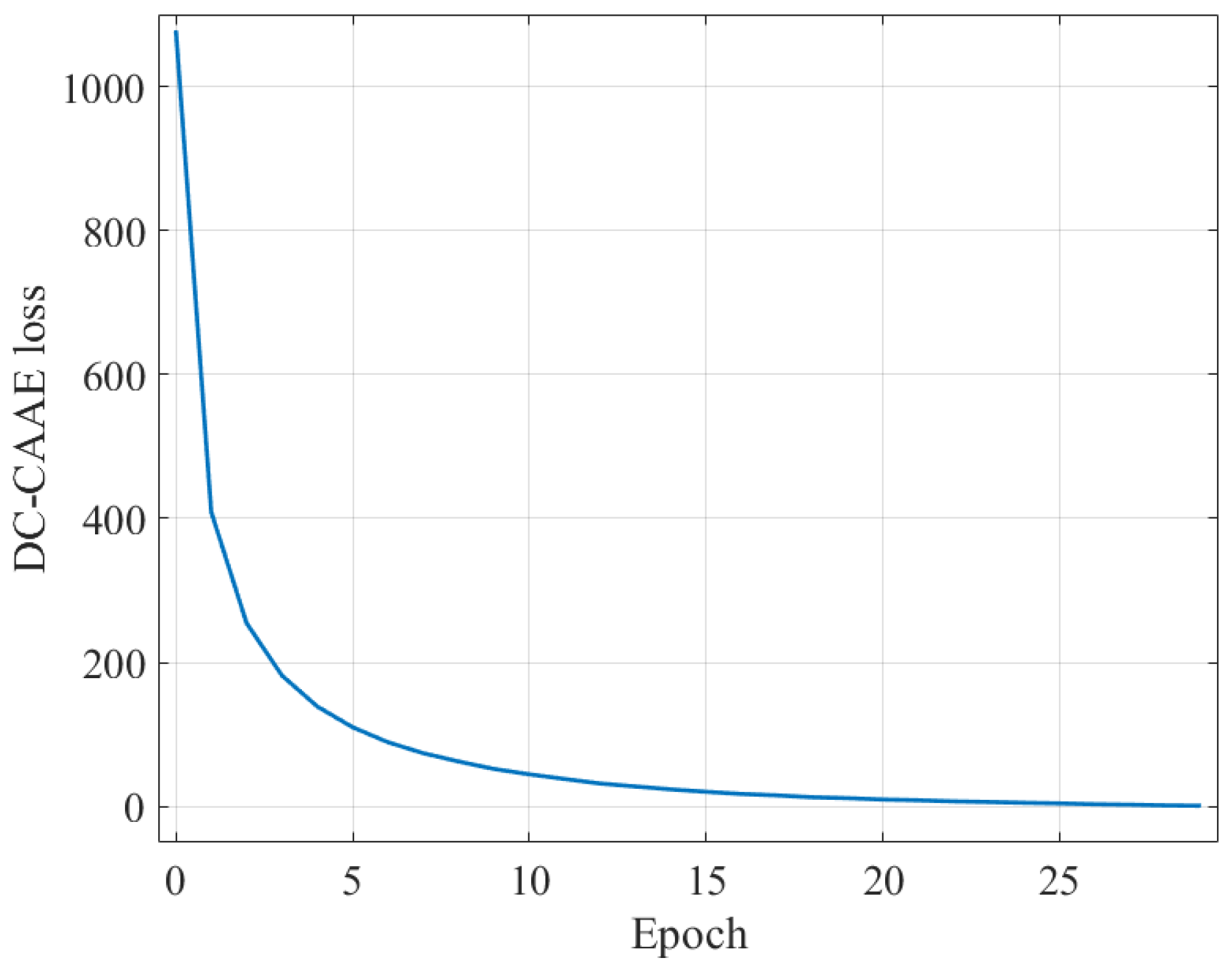
5.2.2. Convergence Analysis
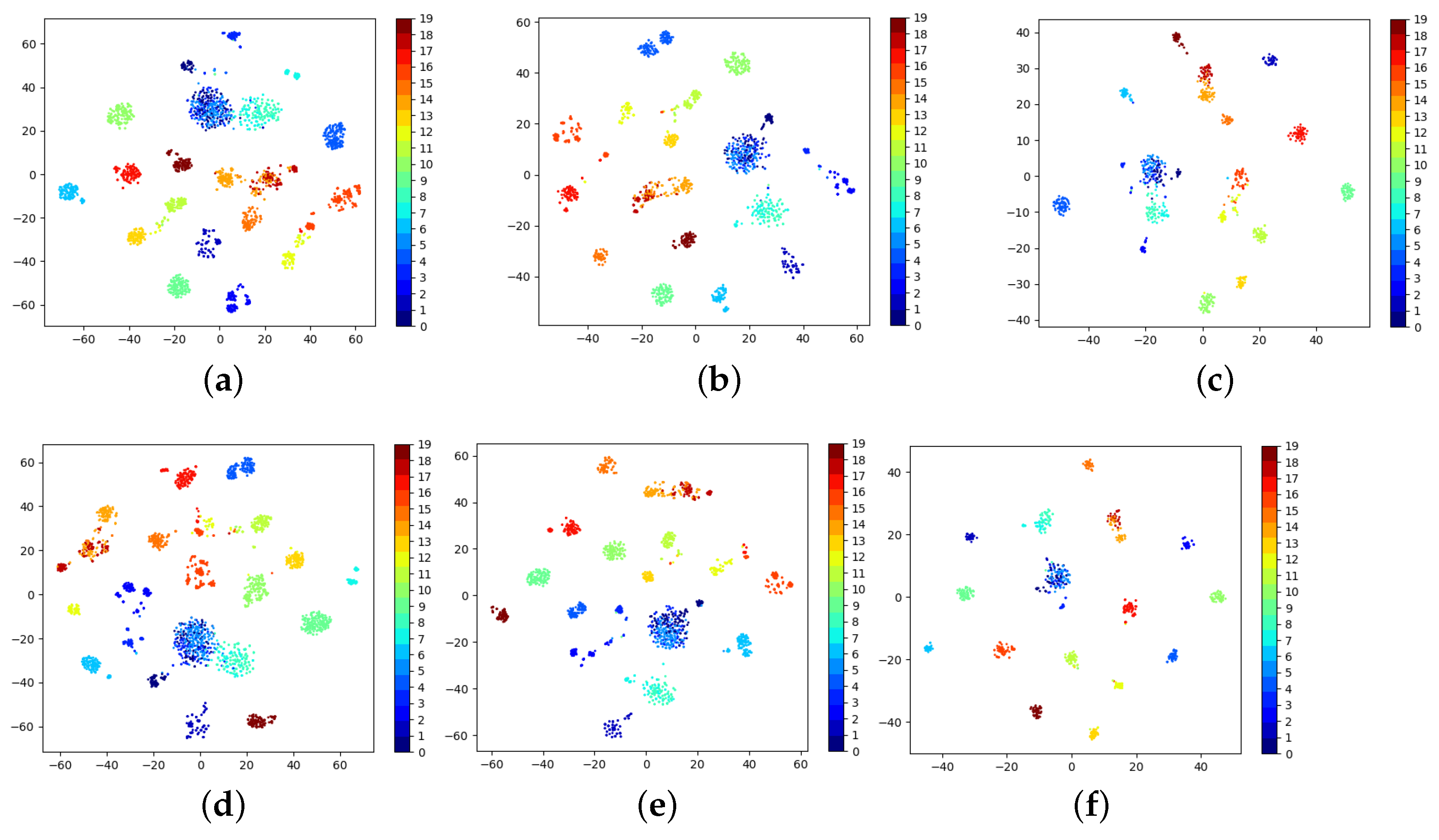
5.2.3. t-SNE Feature Visualizations
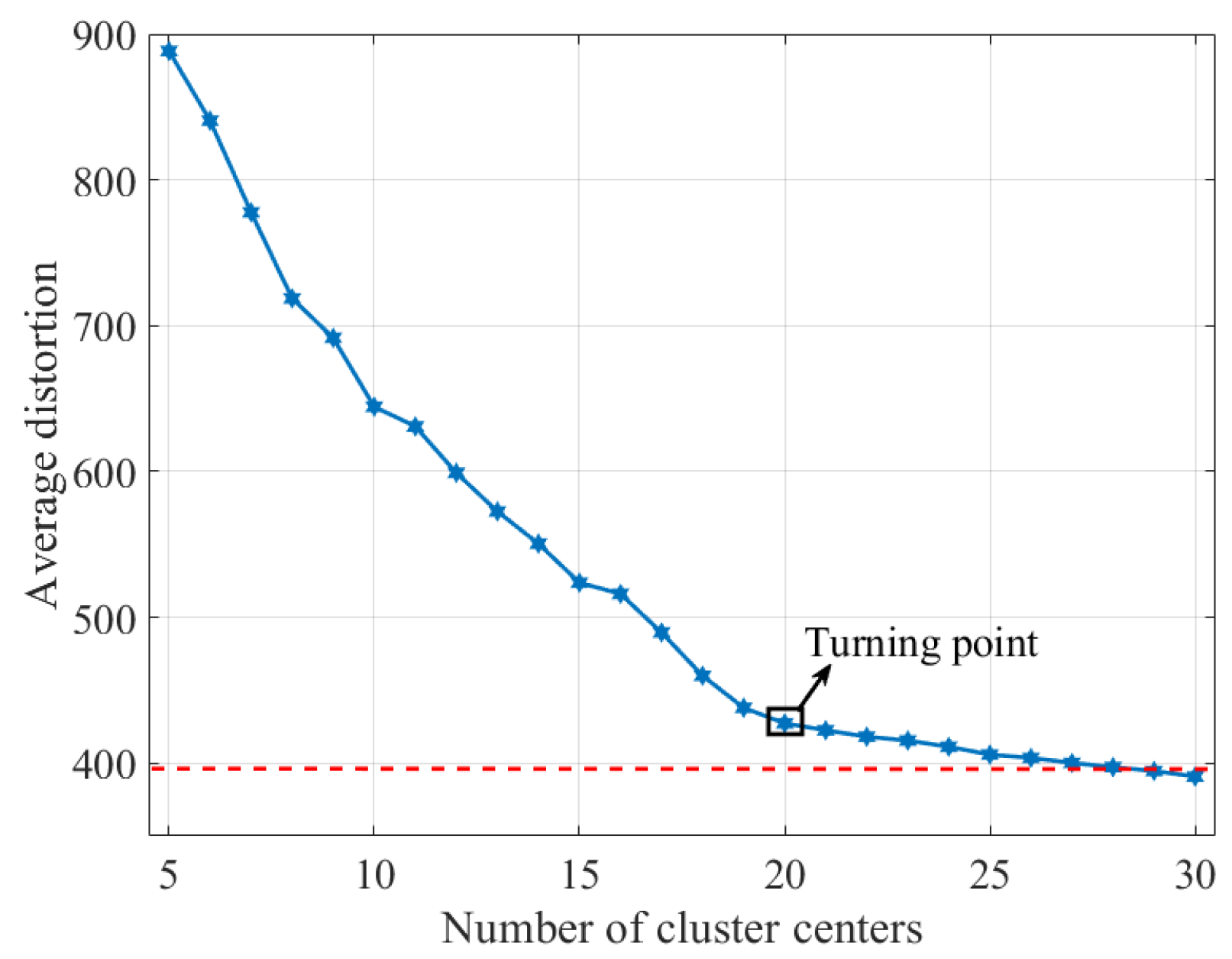
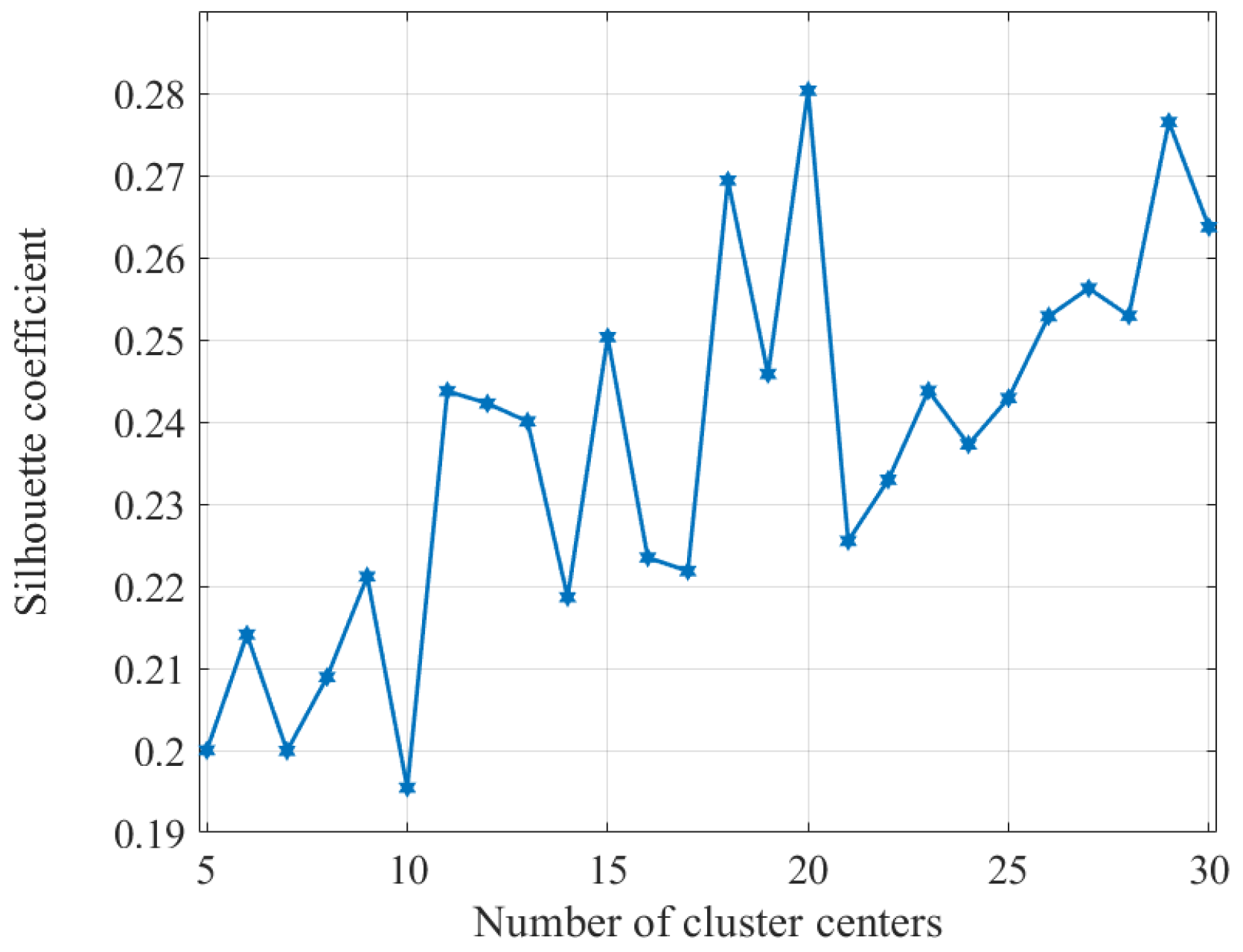
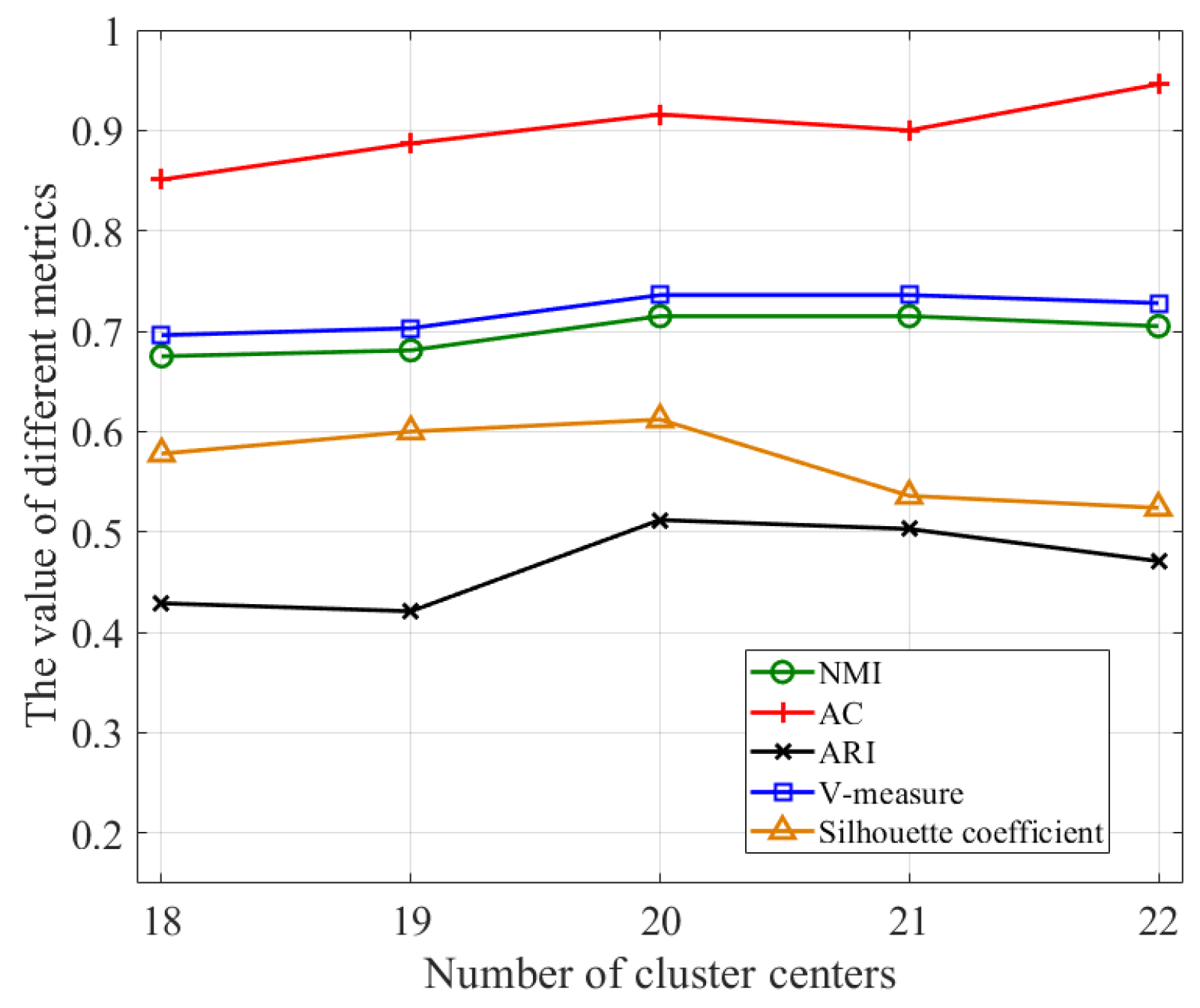
5.2.4. The Influence of the Uncertainty in the Number of Categories on NTC Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| IoE | Internet of everything |
| IoT | Internet of things |
| IDS | Intrusion detection system |
| NTC | Network traffic classification |
| UDP | User Datagram Protocol |
| TCP | Transmission Control Protocol |
| DPI | Deep packet inspection |
| IAIA | Internet Assigned Numbers Authority |
| P2P | Peer-to-peer |
| ML | Machine learning |
| CAAE | Convolutional adversarial autoencoder |
| DC | Deep clustering |
| CAE | Convolutional autoencoder |
| CVAE | Convolutional variational autoencoder |
| OSI | Open System Interconnection |
| FTP | File Transfer Protocol |
| PCA | Principal component analysis |
| LDA | Linear discriminant analysis |
| GMM | Gaussian mixture model |
| NMI | Normalized mutual information |
| AC | Clustering accuracy |
| ARI | Adjusted Rand index |
References
- Nguyen, D.C.; Ding, M.; Pathirana, P.N.; Seneviratne, A.; Li, J.; Niyato, D.; Dobre, O.A.; Poor, H.V. 6G internet of things: A comprehensive survey. IEEE Internet Things J. 2022, 9, 359–383. [Google Scholar] [CrossRef]
- Guo, F.; Yu, F.R.; Zhang, H.; Li, X.; Ji, H.; Leung, V.C.M. Enabling massive IoT toward 6G: A comprehensive survey. IEEE Internet Things J. 2021, 8, 11891–11915. [Google Scholar]
- Lampe, B.; Meng, W. A survey of deep learning-based intrusion detection in automotive applications. Expert Syst. Appl. 2023, 221, 119771. [Google Scholar]
- Li, W.; Meng, W.; Kwok, L.F. Surveying Trust-Based Collaborative Intrusion Detection: State-of-the-Art, Challenges and Future Directions. IEEE Commun. Surv. Tutor. 2022, 24, 280–305. [Google Scholar]
- Zhou, X.; Liang, W.; Li, W.; Yan, K.; Shimizu, S.; Wang, K. Hierarchical adversarial attacks against graph-neural-network-based IoT network intrusion detection system. IEEE Internet Things J. 2022, 9, 9310–9319. [Google Scholar]
- Popoola, S.I.; Ande, R.; Adebisi, B.; Gui, G.; Hammoudeh, M.; Jogunola, O. Federated deep learning for zero-day botnet attack detection in IoT edge devices. IEEE Internet Things J. 2022, 9, 3930–3944. [Google Scholar] [CrossRef]
- Nguyen, T.; Armitage, G. A survey of techniques for internet traffic classification using machine learning. IEEE Commun. Surv. Tutor. 2008, 10, 56–76. [Google Scholar] [CrossRef]
- Dias, K.L.; Pongelupe, M.A.; Caminhas, W.M.; Errico, L. An innovative approach for real-time network traffic classification. Comput. Netw. 2019, 158, 143–157. [Google Scholar] [CrossRef]
- Pasyuk, A.; Semenov, E.; Tyuhtyaev, D. Feature selection in the classification of network traffic flows. In Proceedings of the International Multi-Conference on Industrial Engineering and Modern Technologies (FarEastCon), Vladivostok, Russia, 1–4 October 2019; pp. 1–5. [Google Scholar]
- Moore, A.W.; Zuev, D. Internet traffic classification using bayesian analysis techniques. ACM Sigmetrics Perform. Eval. Rev. 2005, 33, 50–60. [Google Scholar] [CrossRef]
- Min, E.; Guo, X.; Liu, Q.; Zhang, G.; Cui, J.; Long, J. A Survey of Clustering With Deep Learning: From the Perspective of Network Architecture. IEEE Access 2018, 6, 39501–39514. [Google Scholar] [CrossRef]
- Karagiannis, T.; Broido, A.; Faloutsos, M.; Klaffy, K. Transport Layer Identification of P2P Traffic. In Proceedings of the 4th ACM SIGCOMM Conference on Internet Measurement (IMC 2004), Taormina Sicily, Italy, 25–27 October 2004; pp. 121–134. [Google Scholar]
- Dusi, M.; Gringoli, F.; Salgarelli, L. Quantifying the accuracy of the ground truth associated with Internet traffic traces. Comput. Netw. 2011, 55, 1158–1167. [Google Scholar] [CrossRef]
- Dreger, H.; Feldmann, A.; Mai, M.; Paxson, V.; Sommer, R.R. Dynamic application layer protocol analysis for network intrusion detection. In Proceedings of the USENIX Security Symposium, Vancouver, BC, Canada, 31 July–4 August 2006; pp. 257–272. [Google Scholar]
- Madhukar, A.; Williamson, C. A longitudinal study of P2P traffic classification. In Proceedings of the 14th IEEE International Symposium on Modeling, Analysis, and Simulation, Monterey, CA, USA, 11–14 September 2006; pp. 179–188. [Google Scholar]
- Paxson, V. Empirically derived analytic models of wide-area TCP connections. IEEE/ACM Trans. Netw. 1994, 2, 316–336. [Google Scholar] [CrossRef]
- Sadeghzadeh, A.M.; Shiravi, S.; Jalili, R. Adversarial network traffic: Towards evaluating the robustness of deep-learning-based network traffic classification. IEEE Trans. Netw. Serv. Manag. 2021, 18, 1962–1976. [Google Scholar] [CrossRef]
- Ma, W.; Qi, C.; Zhang, Z.; Cheng, J. Sparse channel estimation and hybrid precoding using deep learning for millimeter wave massive MIMO. IEEE Trans. Commun. 2020, 68, 2838–2849. [Google Scholar] [CrossRef]
- Zhao, R.; Gui, G.; Xue, Z.; Yin, J.; Ohtsuki, T.; Adebisi, B.; Gacanin, H. A novel intrusion detection method based on lightweight neural network for internet of things. IEEE Internet Things J. 2022, 9, 9960–9972. [Google Scholar]
- Ning, J.; Gui, G.; Wang, Y.; Yang, J.; Adebisi, B.; Ci, S.; Haris, G.; Gacanin, H. Malware traffic classification using domain adaptation and ladder network for secure industrial internet of things. IEEE Internet Things J. 2022, 9, 17058–17069. [Google Scholar]
- Huang, P.; Huang, Y.; Wang, W.; Wang, L. Deep embedding network for clustering. In Proceedings of the 22nd International Conference on Pattern Recognition, Stockholm, Sweden, 24–28 August 2014; pp. 1532–1537. [Google Scholar]
- Li, P.; Chen, Z.; Yang, L.T.; Gao, J.; Zhang, Q.; Deen, M.J. An improved stacked auto-encoder for network traffic flow classification. IEEE Netw. 2018, 32, 22–27. [Google Scholar]
- Shah, S.; Koltun, V. Deep Continuous Clustering. 2018. Available online: https://arxiv.org/abs/1803.01449 (accessed on 5 March 2018).
- Srivastava, R.; Greff, K.; Schmidhuber, J. Training very deep networks. In Proceedings of the Neural Information Processing Systems (NIPS), Red Hook, NY, USA, 7–12 December 2015; pp. 2377–2385. [Google Scholar]
- Thies, J.; Alimohammad, A. Compact and low-power neural spike compression using undercomplete autoencoders. IEEE Trans. Neural Syst. Rehabil. Eng. 2019, 27, 1529–1538. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhu, M.; Zeng, X.; Ye, X.; Sheng, Y. Malware traffic classification using convolutional neural network for representation learning. In Proceedings of the International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; pp. 712–717. [Google Scholar]
- Ren, Y.; Pu, J.; Yang, Z.; Li, G.; Pu, X.; Yu, P.; He, L. Deep Clustering: A Comprehensive Survey. 2022. Available online: https://arxiv.org/abs/2210.04142 (accessed on 9 October 2022).
- Hoang, D.H.; Nguyen, H.D. Detecting anomalous network traffic in IoT networks. In Proceedings of the International Conference on Advanced Communication Technology (ICACT), PyeongChang, Republic of Korea, 17–20 February 2019; pp. 1143–1152. [Google Scholar]
- Peng, X.; Xiao, S.; Feng, J.; Yau, W.-Y.; Yi, Z. Deep subspace clustering with sparsity prior. In Proceedings of the International Joint Conferences on Artificial Intelligence Organization (IJCAI), New York, NY, USA, 9–15 July 2016; pp. 1925–1931. [Google Scholar]
- Yao, R.; Liu, C.; Zhang, L.; Peng, P. Unsupervised anomaly detection using variational auto-encoder based feature extraction. In Proceedings of the IEEE International Conference on Prognostics and Health Management (ICPHM), San Francisco, CA, USA, 17–20 June 2019; pp. 1–7. [Google Scholar]
- Yang, B.; Fu, X.; Sidiropoulos, N.D.; Hong, M. Towards K-means-friendly spaces: Simultaneous deep learning and clustering. In Proceedings of the 34th International Conference on Machine Learning (ICML 2017), Sydney, Australia, 6–11 August 2017; pp. 3861–3870. [Google Scholar]
- Guo, X.; Liu, X.; Zhu, E.; Zhu, X.; Li, M.; Xu, X.; Yin, J. Adaptive self-paced deep clustering with data augmentation. IEEE Trans. Knowl. Data Eng. 2020, 32, 1680–1693. [Google Scholar] [CrossRef]
- Rabiner, L. Combinatorial optimization: Algorithms and complexity. IEEE Trans. Acoust. Speech Signal Process. 1984, 32, 1258–1259. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Benign Data | Training Det | Testing Set | Malicious Data | Training Set | Testing Set |
|---|---|---|---|---|---|
| BitTorrent | 5049 | 1716 | Cridex | 5595 | 1805 |
| Facetime | 4045 | 1355 | Geodo | 4543 | 1490 |
| FTP | 4660 | 1542 | Htbot | 4346 | 1384 |
| Gmail | 5828 | 1938 | Miuref | 3476 | 1145 |
| MyDQL | 4911 | 1606 | Neris | 5714 | 1940 |
| Outlook | 5014 | 1758 | Nsis-ay | 4100 | 1362 |
| Skype | 4275 | 1414 | Shifu | 6451 | 2220 |
| SMB | 4248 | 1448 | Tinba | 5772 | 1882 |
| 4510 | 1496 | Virus | 4399 | 1473 | |
| World of Warcraft | 5313 | 1782 | Zeus | 4075 | 1353 |
| Layer | Encoder | Generator | Discriminator |
|---|---|---|---|
| Input | Input | Input | Input |
| Layer 1 | Conv2d (1, 8, 3, 2, 1) | Linear (100, 1000) | Linear (100, 1000) |
| Layer 2 | Conv2d (8, 16, 3, 2, 1) | Linear (1000, 288) | Linear (1000, 1000) |
| Layer 3 | Conv2d (16, 32, 3, 2, 0) | ConvTranspose2d (32, 16, 3, 2, 0) | Linear (1000, 1) |
| Layer 4 | Linear (288, 1000) | ConvTranspose2d (16, 8, 3, 2, 1) | None |
| Layer 5 | Linear (1000, 100) | ConvTranspose2d (8, 1, 3, 2, 1) | None |
| Output | Output | Output | Output |
| Parameter | Value | |
|---|---|---|
| Dataset | USTC-TFC2016 | |
| Input data dimension | (28, 28, 1) | |
| Hidden feature dimension | 100 | |
| Environment | Python 3.10.4, Scikit-learn 1.1.0, Torch 1.11.0, Numpy 1.22.3 | |
| Device | GeForce RTX 2080 Ti | |
| Pretraining hyperparameters | Optimizer | Adam |
| Weight_decay | 0 | |
| Batch size | 128 | |
| Learning rate | 0.00001 | |
| Epoch | 80 | |
| Deep clustering hyperparameters | Optimizer | Adam |
| Weight_decay | 0 | |
| Batch size | 128 | |
| Learning rate | 0.0001 | |
| Epoch | 30 | |
| Methods | NMI | AC | Silhouette Coefficient | ARI | V-Measure |
|---|---|---|---|---|---|
| PCA | 0.685 | 0.494 | 0.326 | 0.345 | 0.685 |
| CAE | 0.887 | 0.824 | 0.526 | 0.740 | 0.887 |
| CVAE | 0.888 | 0.830 | 0.492 | 0.758 | 0.889 |
| CAAE | 0.882 | 0.888 | 0.408 | 0.796 | 0.890 |
| DC-CAE | 0.873 | 0.844 | 0.518 | 0.736 | 0.873 |
| DC-CVAE | 0.890 | 0.857 | 0.481 | 0.753 | 0.891 |
| DC-CAAE (proposed) | 0.911 | 0.922 | 0.422 | 0.844 | 0.917 |
| Methods | NMI | AC | Silhouette Coefficient | ARI | V-Measure |
|---|---|---|---|---|---|
| Minibatch k-means clustering | 0.894 | 0.905 | 0.418 | 0.829 | 0.901 |
| Spectral clustering | 0.908 | 0.908 | 0.444 | 0.826 | 0.915 |
| BIRCH | 0.903 | 0.906 | 0.427 | 0.819 | 0.910 |
| GMM | 0.904 | 0.908 | 0.428 | 0.822 | 0.911 |
| k-Means clustering | 0.911 | 0.922 | 0.422 | 0.844 | 0.917 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, W.; Zhang, L.; Zhang, X.; Wang, Y.; Liu, P.; Gui, G. Intelligent Unsupervised Network Traffic Classification Method Using Adversarial Training and Deep Clustering for Secure Internet of Things. Future Internet 2023, 15, 298. https://doi.org/10.3390/fi15090298
Zhang W, Zhang L, Zhang X, Wang Y, Liu P, Gui G. Intelligent Unsupervised Network Traffic Classification Method Using Adversarial Training and Deep Clustering for Secure Internet of Things. Future Internet. 2023; 15(9):298. https://doi.org/10.3390/fi15090298
Chicago/Turabian StyleZhang, Weijie, Lanping Zhang, Xixi Zhang, Yu Wang, Pengfei Liu, and Guan Gui. 2023. "Intelligent Unsupervised Network Traffic Classification Method Using Adversarial Training and Deep Clustering for Secure Internet of Things" Future Internet 15, no. 9: 298. https://doi.org/10.3390/fi15090298