





by
and

Big Data Cogn. Comput. 2023, 7(3), 147; https://doi.org/10.3390/bdcc7030147 - 30 Aug 2023
Abstract
►
Show Figures
The future of innovative robotic technologies and artificial intelligence (AI) in pharmacy and medicine is promising, with the potential to revolutionize various aspects of health care. These advances aim to increase efficiency, improve patient outcomes, and reduce costs while addressing pressing challenges such
[...] Read more.
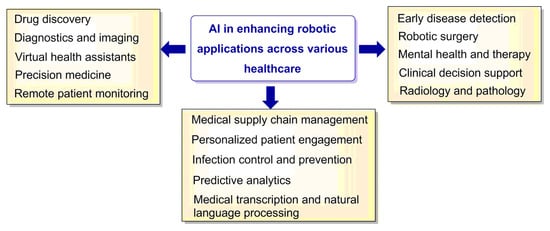
The future of innovative robotic technologies and artificial intelligence (AI) in pharmacy and medicine is promising, with the potential to revolutionize various aspects of health care. These advances aim to increase efficiency, improve patient outcomes, and reduce costs while addressing pressing challenges such as personalized medicine and the need for more effective therapies. This review examines the major advances in robotics and AI in the pharmaceutical and medical fields, analyzing the advantages, obstacles, and potential implications for future health care. In addition, prominent organizations and research institutions leading the way in these technological advancements are highlighted, showcasing their pioneering efforts in creating and utilizing state-of-the-art robotic solutions in pharmacy and medicine. By thoroughly analyzing the current state of robotic technologies in health care and exploring the possibilities for further progress, this work aims to provide readers with a comprehensive understanding of the transformative power of robotics and AI in the evolution of the healthcare sector. Striking a balance between embracing technology and preserving the human touch, investing in R&D, and establishing regulatory frameworks within ethical guidelines will shape a future for robotics and AI systems. The future of pharmacy and medicine is in the seamless integration of robotics and AI systems to benefit patients and healthcare providers.
Full article

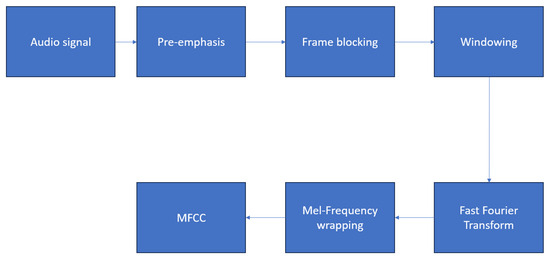
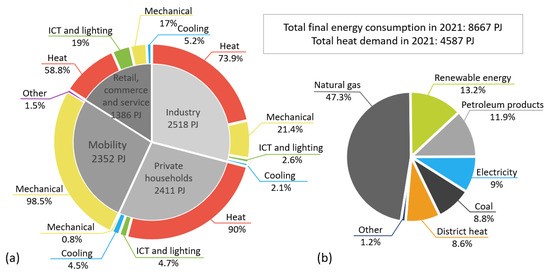
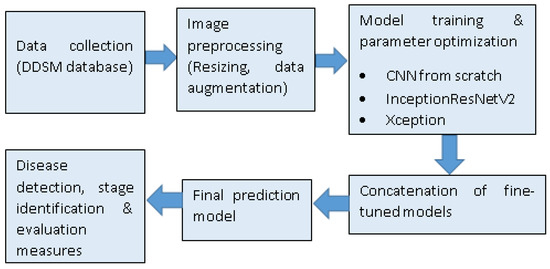
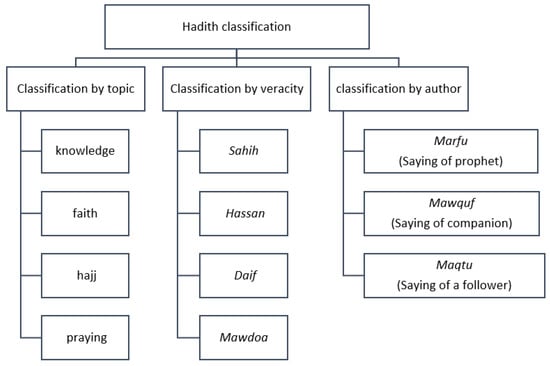
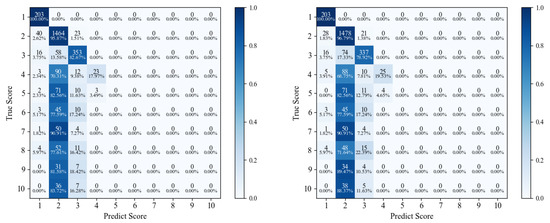
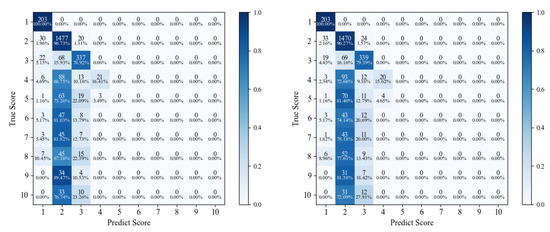
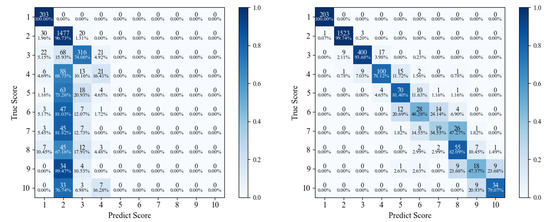
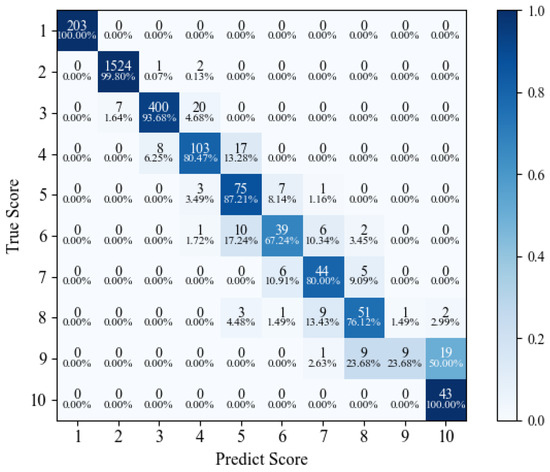
Figure 1










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}