

BioMedInformatics 2023, 3(3), 724-751; https://doi.org/10.3390/biomedinformatics3030047 (registering DOI) - 01 Sep 2023
Abstract
Tuberculosis (TB) is one of the leading infectious causes of death worldwide. The effective management and public health control of this disease depends on early detection and careful treatment monitoring. For many years, the microscopy-based analysis of sputum smears has been the most
[...] Read more.
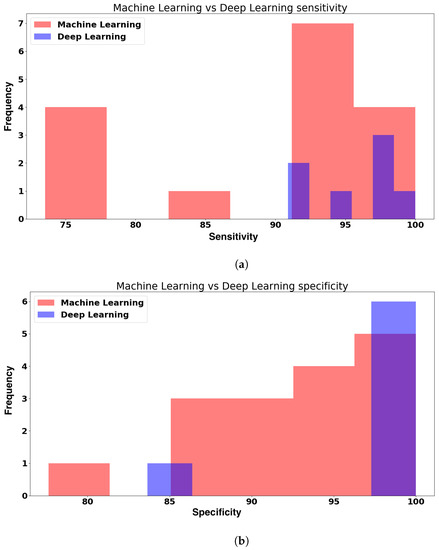
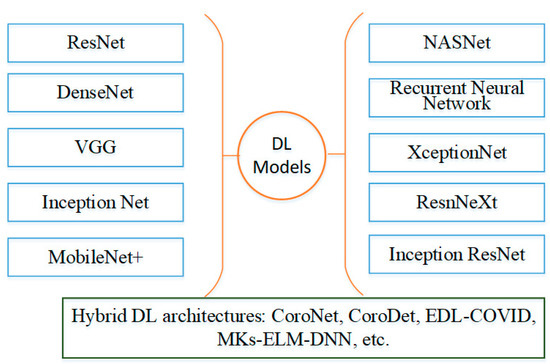
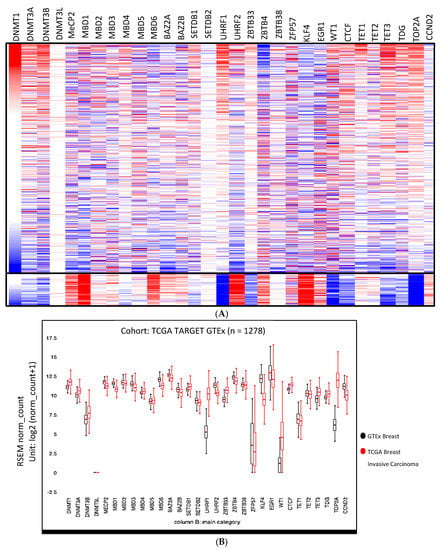
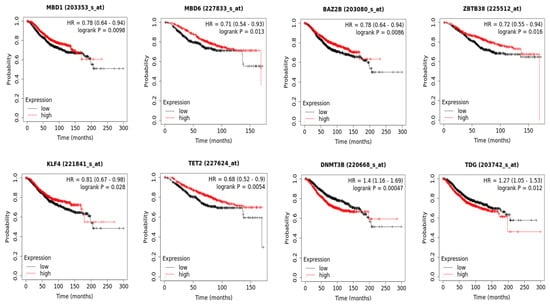
Tuberculosis (TB) is one of the leading infectious causes of death worldwide. The effective management and public health control of this disease depends on early detection and careful treatment monitoring. For many years, the microscopy-based analysis of sputum smears has been the most common method to detect and quantify Mycobacterium tuberculosis (Mtb) bacteria. Nonetheless, this form of analysis is a challenging procedure since sputum examination can only be reliably performed by trained personnel with rigorous quality control systems in place. Additionally, it is affected by subjective judgement. Furthermore, although fluorescence-based sample staining methods have made the procedure easier in recent years, the microscopic examination of sputum is a time-consuming operation. Over the past two decades, attempts have been made to automate this practice. Most approaches have focused on establishing an automated method of diagnosis, while others have centred on measuring the bacterial load or detecting and localising Mtb cells for further research on the phenotypic characteristics of their morphology. The literature has incorporated machine learning (ML) and computer vision approaches as part of the methodology to achieve these goals. In this review, we first gathered publicly available TB sputum smear microscopy image sets and analysed the disparities in these datasets. Thereafter, we analysed the most common evaluation metrics used to assess the efficacy of each method in its particular field. Finally, we generated comprehensive summaries of prior work on ML and deep learning (DL) methods for automated TB detection, including a review of their limitations.
Full article
(This article belongs to the Section Clinical Informatics)
►
Show Figures
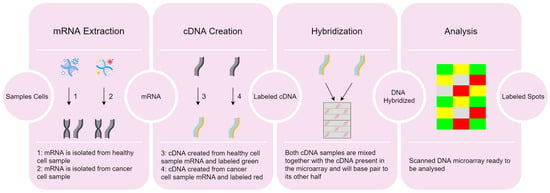
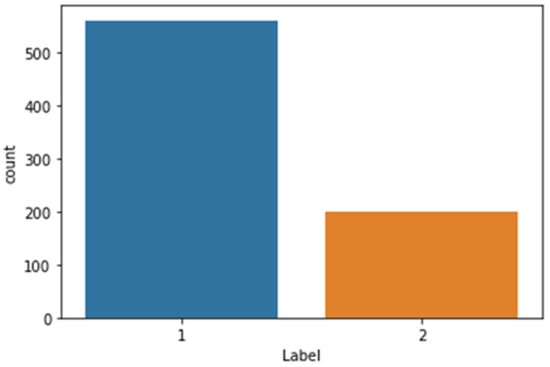
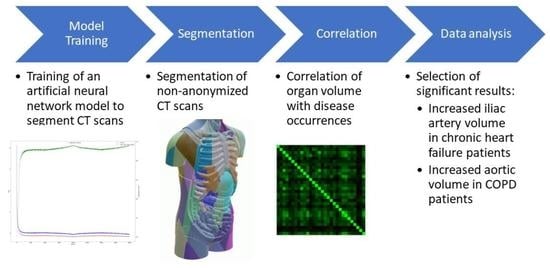
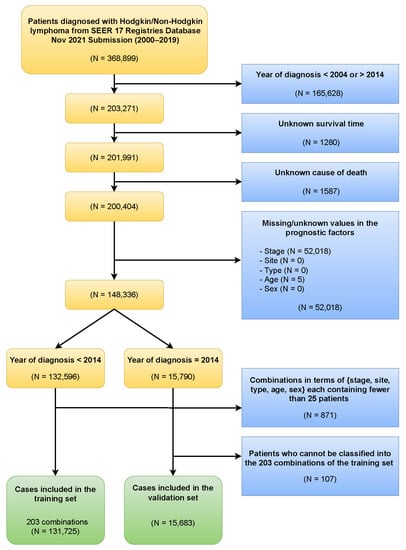
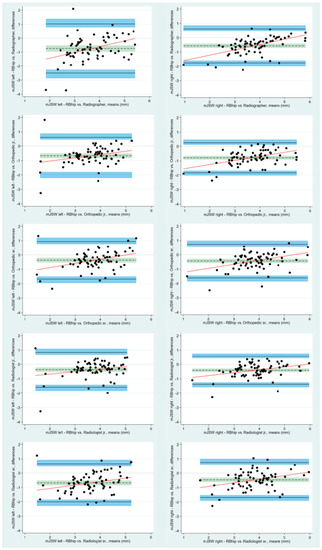
Figure 1














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}