

by
and


Econometrics 2023, 11(3), 22; https://doi.org/10.3390/econometrics11030022 - 30 Aug 2023
Abstract
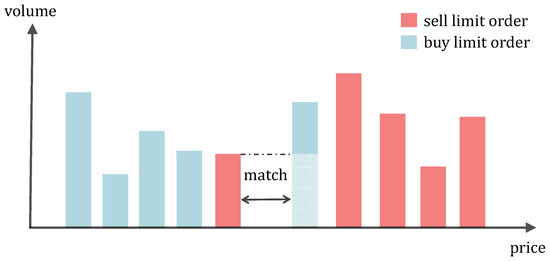
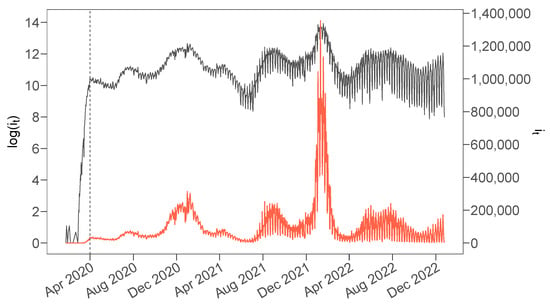
Detecting pump-and-dump schemes involving cryptoassets with high-frequency data is challenging due to imbalanced datasets and the early occurrence of unusual trading volumes. To address these issues, we propose constructing synthetic balanced datasets using resampling methods and flagging a pump-and-dump from the moment of
[...] Read more.
Detecting pump-and-dump schemes involving cryptoassets with high-frequency data is challenging due to imbalanced datasets and the early occurrence of unusual trading volumes. To address these issues, we propose constructing synthetic balanced datasets using resampling methods and flagging a pump-and-dump from the moment of public announcement up to 60 min beforehand. We validated our proposals using data from Pumpolymp and the CryptoCurrency eXchange Trading Library to identify 351 pump signals relative to the Binance crypto exchange in 2021 and 2022. We found that the most effective approach was using the original imbalanced dataset with pump-and-dumps flagged 60 min in advance, together with a random forest model with data segmented into 30-s chunks and regressors computed with a moving window of 1 h. Our analysis revealed that a better balance between sensitivity and specificity could be achieved by simply selecting an appropriate probability threshold, such as setting the threshold close to the observed prevalence in the original dataset. Resampling methods were useful in some cases, but threshold-independent measures were not affected. Moreover, detecting pump-and-dumps in real-time involves high-dimensional data, and the use of resampling methods to build synthetic datasets can be time-consuming, making them less practical.
Full article








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}