




by
, , , , and



Informatics 2023, 10(3), 71; https://doi.org/10.3390/informatics10030071 (registering DOI) - 31 Aug 2023
Abstract
►
Show Figures
Vulnerabilities in cyber defense in the countries of the Latin American region have favored the activities of cybercriminals from different parts of the world who have carried out a growing number of cyberattacks that affect public and private services and compromise the integrity
[...] Read more.
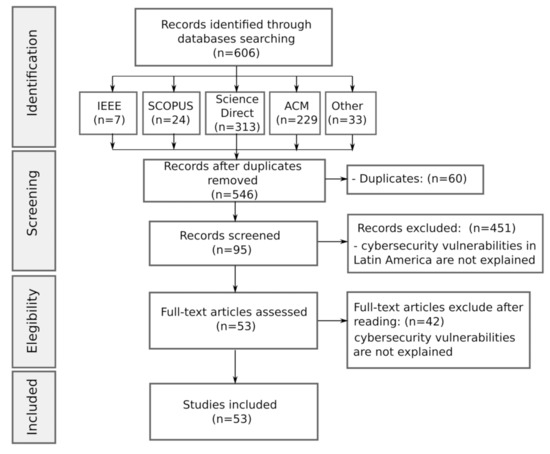
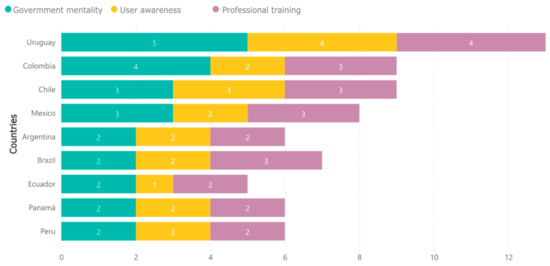
Vulnerabilities in cyber defense in the countries of the Latin American region have favored the activities of cybercriminals from different parts of the world who have carried out a growing number of cyberattacks that affect public and private services and compromise the integrity of users and organizations. This article describes the most representative vulnerabilities related to cyberattacks that have affected different sectors of countries in the Latin American region. A systematic review of repositories and the scientific literature was conducted, considering journal articles, conference proceedings, and reports from official bodies and leading brands of cybersecurity systems. The cybersecurity vulnerabilities identified in the countries of the Latin American region are low cybersecurity awareness, lack of standards and regulations, use of outdated software, security gaps in critical infrastructure, and lack of training and professional specialization.
Full article

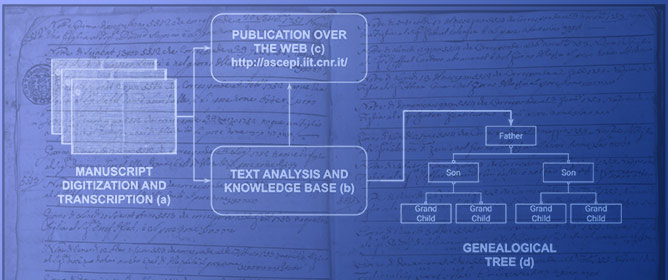
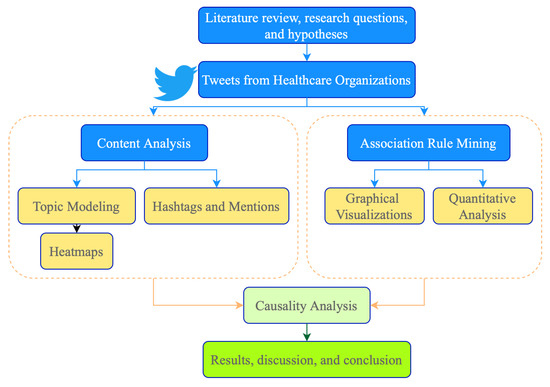
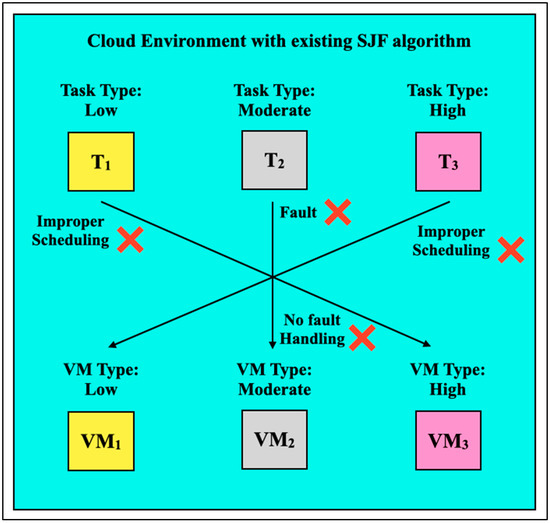
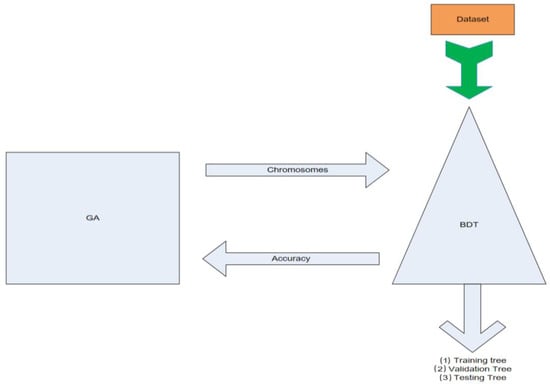
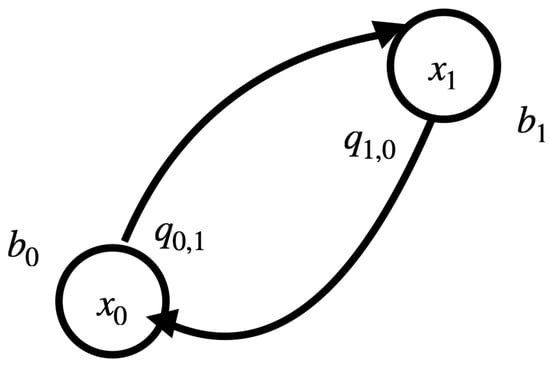
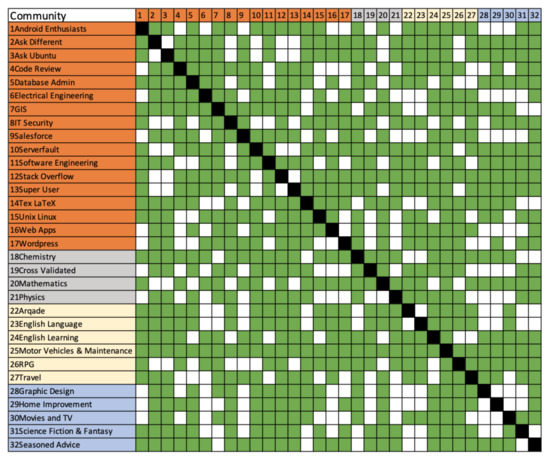
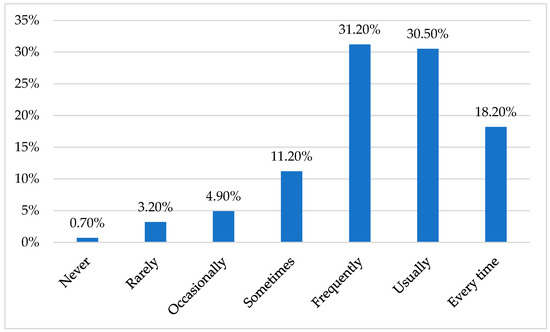
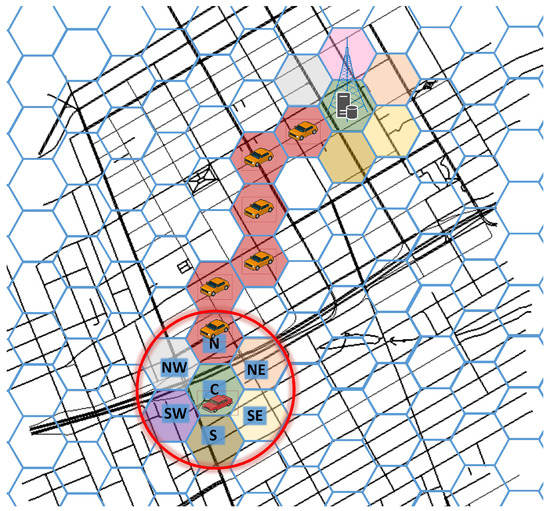
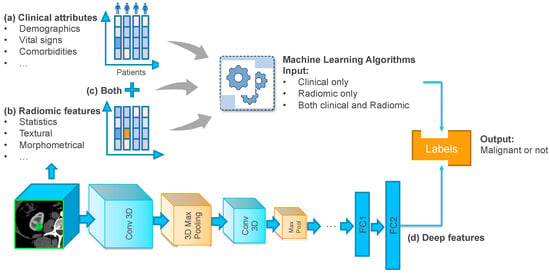
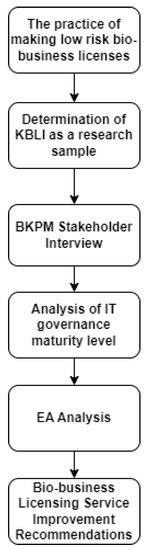
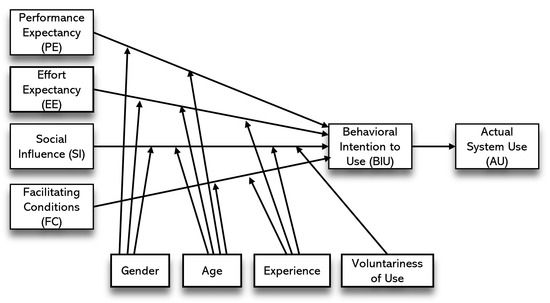
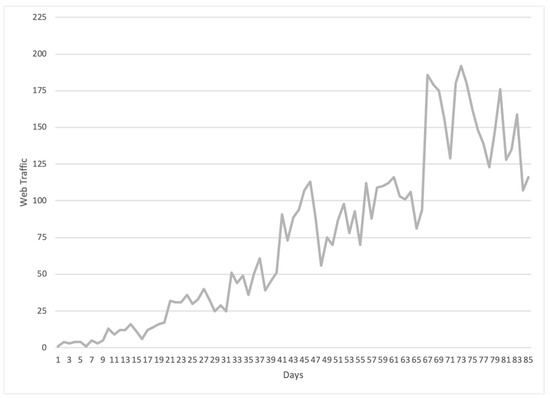
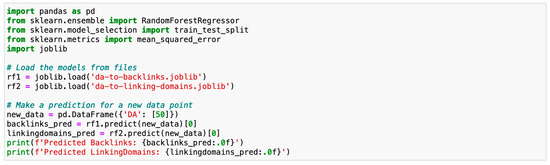
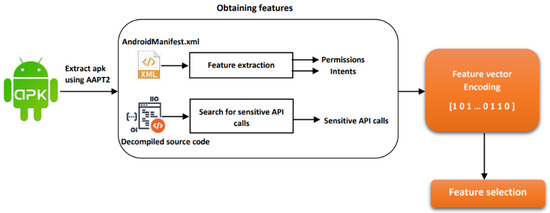
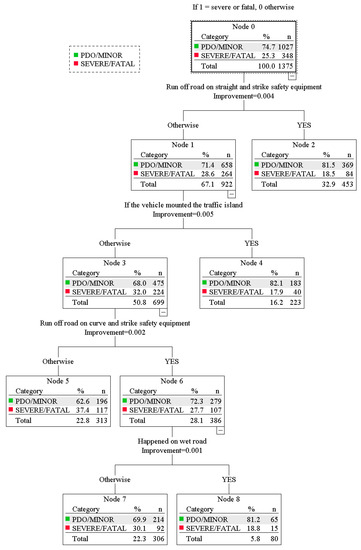
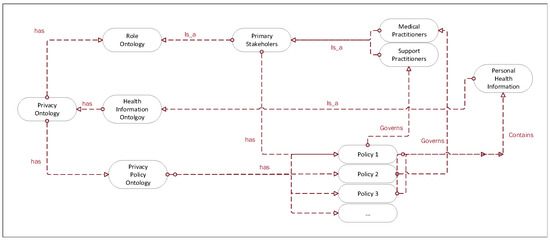
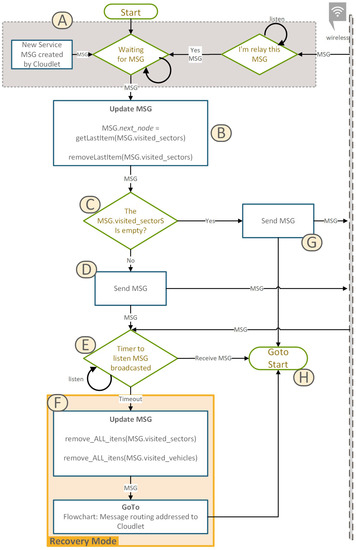
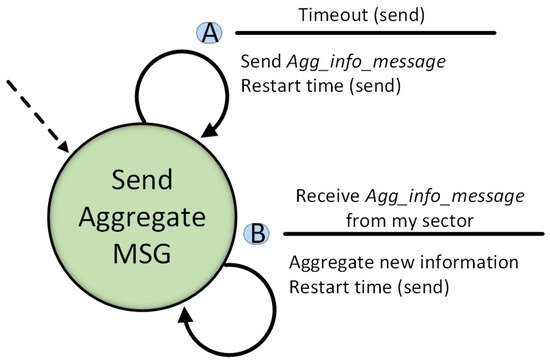
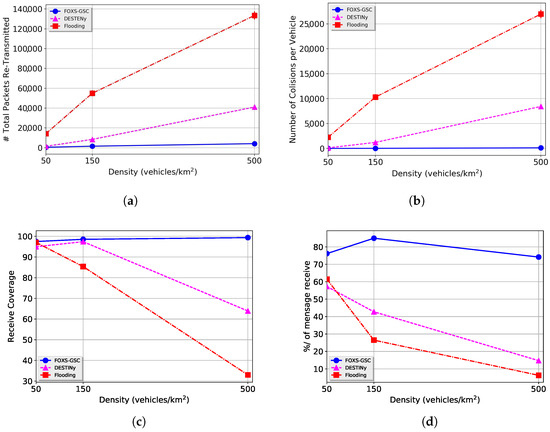
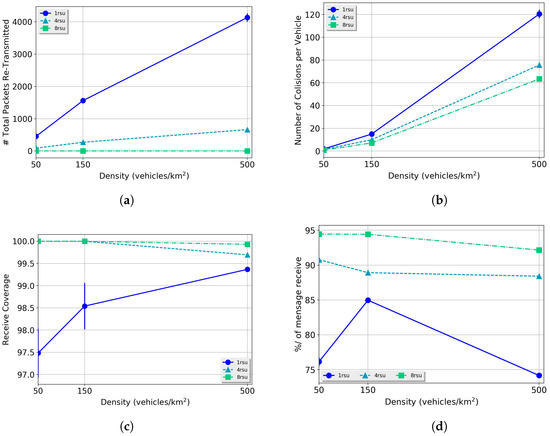
Figure 1














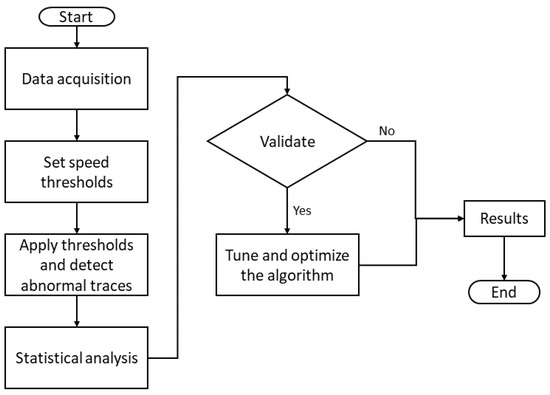



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
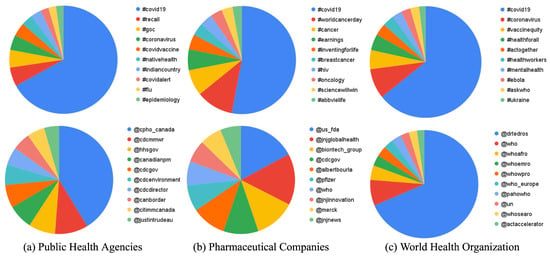
{kind=link}
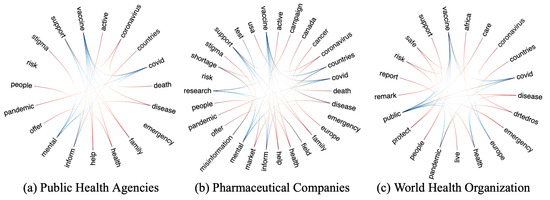
{kind=link}
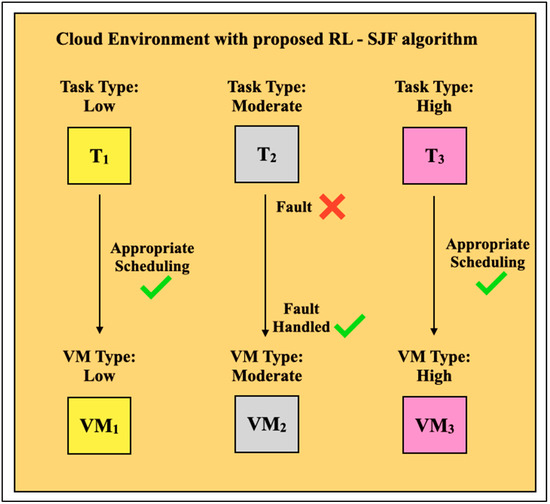
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}